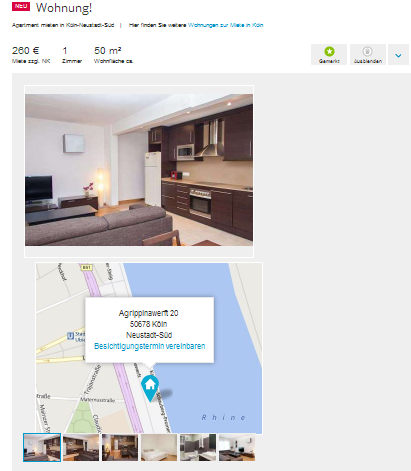
Meine Frage war reichlich unglücklich formuliert: Natürlich geht es nicht um eine nachträgliche Anreicherung von Datensätzen mit unversorgtem Merkmalswert, sondern um die Verteilung von Datensätzen mit initialem Merkmalswert auf solche mit nicht-initialem. Also gewissermaßen von Top-Down-Verteilung innerhalb eines Merkmals. Was aber offenbar realisierbar ist (siehe Screenshot).
↧